Why?
Just like you need to add memory or drives, you need to add speed.
But you can not. Why not? It is called coherence. Computer caches must talk.
However, software tasks do not talk. Infinite tasks run concurrently on a uniprocessor.
The answer to why solves a hardware issue that predates 1965.
Since 1965 the question has been, "How do you make caches talk efficiently?"
Answer - Infinite computers do not have to talk at all.
Coherence goes poof.
Because...
In
1965, IBM announced a multiprocessor. It had two processors and two
caches and the caches talked to synchronize. IBM announced it as quad,
but a quad was never built. The algorithm has been optimized, but
not redesigned.
In 1970 the creation of relational databases resulted in the recognition that data should be stored in one location. Store data in one place!
In 1973 the creation of the conditional compare and swap instruction enabled most software locks to be eliminated.
However work on cache synchronization, now termed cache coherence, continued with an algorithm that was conceived before 1965.
This
new computer design incorporates those two software changes into the
hardware, resulting in processors that do not communicate; true parallel processing. The design requires a change to the hardware implementation of the conditional compare and swap instruction.
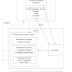
Coherent Memory maintains data integrity without cache coherence
How
Software recognizes that some data is shared, meaning that it is R/W for other processes. The software handles this data differently. The hardware would also perform better if it handled data in two ways. Step 1 is a new allocation instruction that allocates data for either shared processing or non-shared processing. Coherence is immediately reduced because non-shared data does not require coherence. (Load balancing can be handled by cast out, but is not needed given sufficient processors.) Having sufficient processors changes everything because multitasking addresses insufficient processors. Multitasking has a queue, impacting elapsed time.
Impact
Multi-core processors can finally exceed the 1965 design limit of four. The new limit is infinite.
Step 1 - Reduces coherence.
Step 2 - Eliminates all remaining coherence.
History
Cache coherence and an interlock prevent core processors from being connected solely to the main memory bus.
The IBM manual linked below explains the entire issue on page 104. The 2nd and 3rd paragraphs explain buffer (cache) invalidation. The next to last paragraph explains the processor interlock. The interlock is for CS, CDS, and TS instructions. These are HSP instructions. Implementing an HSP that does not contain an interlock creates a coherence-free swap (CFS). However removing this interlock has been of no benefit because shared data in cache memory requires cache coherence.
However if shared data is not stored in cache memory, it does not require cache coherence. Then no interlock enables processors to connect directly to the main memory bus.
IBM 3033 Processor Complex April 1979
Chronology
Chronology of disappearance of Coherence
Design Notes
- Step 1 permits an exclusive cache, which requires neither coherence nor write-through.
- Step 1, in conjunction with replacing the HSP with a CFS, allows the hardware to handle shared data without a cache and therefore without coherence.
- Coherence is solely for hardware update integrity. Because of multitasking, software already protects from changes made by other tasks. Software update integrity only requires the interlock. Eliminating
the interlock can be done either by serialization or with an
uninterruptible swap in memory, but it can not be implemented in the
cache because that causes coherence.
- Eliminating both the interlock and cache coherence enables core processors to be connected solely to the main memory bus.
- The swap could be performed by a memory processor. One would be required for each memory bank.
- More
cost efficient is to have an instruction that allocates swap memory so
only the swap memory bank would require a memory processor..
- If
swap memory is only altered with a CFS, then a processor could be
dedicated to handling swap instructions. This processor would be able to
keep all the swap areas in its cache.
- Additional latency is restricted to the CFS instructions.
- Implementing
step 1 alone will reduce both parts of coherence which consists of a
write-through and invalidation. The benefit is expected to be great
enough that that Step 2 will not need to be modeled for licensing.